
This rather fun and unusual module exploits the power of V/Bar based sequencing to provide a hands-on way of controlling Adroit sequencers and other time-related modules.
Its name “Scratch” refers to DJ scratching – where a vinyl disc is manipulated by hand to move the recording back and forth under the stylus.
The large slider provides this function by determining the voltage output to the V/BAR OUT socket.
The START knob sets the lower limit of the slider’s output to between 1 and 16 volts – in other words bar 1 to bar 16.
The RANGE knob determines the range of the slider and can be set to between 1 and 16 volts – in other words 1 to 16 bars later than the bar set by START.
So when both knobs are set at minimum the V/BAR OUT voltage will vary between 1 and 2 volts and therefore will make the slider control which step of a connected Adroit sequencer (such as CV Sequencer or Rhythm Sequencer) is active.
As another example setting the START knob to Bar 1 and the RANGE knob to 8 Bars would allow you to sweep a Progression module through an 8 bar long chord progression to help you quickly perfect particular chord choices.
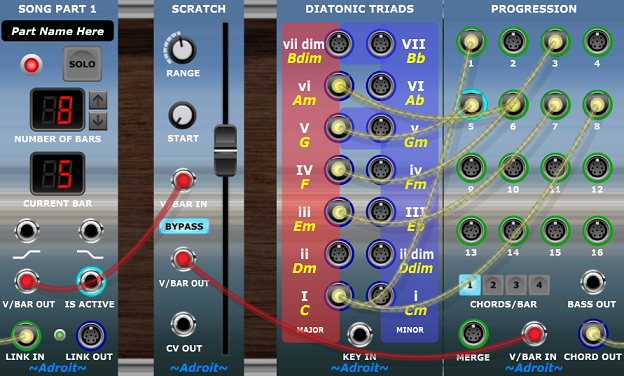
When the BYPASS button is engaged the module passes any voltage fed to the V/BAR IN socket directly to the V/BAR OUT.
So this button functions rather like the DJ’s slipmat. When BYPASS is on the Scratch module has no effect and the sequencers or other modules connected to V/BAR OUT are driven by the V/BAR IN voltage (which would usually come from a Song Part Module, a time splitter or perhaps an AHR Generator).
The idea is to allow you to temporarily override the default timing to use the slider to manually move backwards and forwards in time while adjusting a particular set of events – a chord progression, a set of notes or drum hits or perhaps to tweak a CV Sequencer’s modulation of a parameter.
As well as being very useful for editing this module has performance potential too.
One application is to feed the V/Bar output to one or more CV Sequencers and use the slider to sweep through prepared patterns of CV changes. In this way complex changes to multiple parameters can be made by adjusting just one slider.
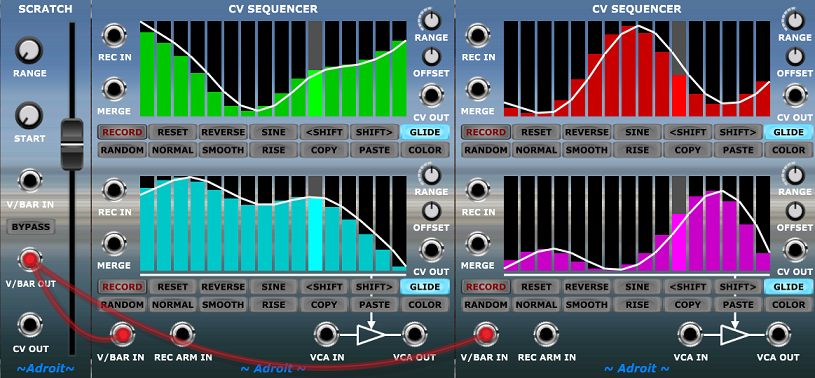
Note that engaging the GLIDE buttons on connected CV Sequencers will make them interpolate control voltages between steps so that the slider delivers smooth changes to parameters rather than sudden jumps.
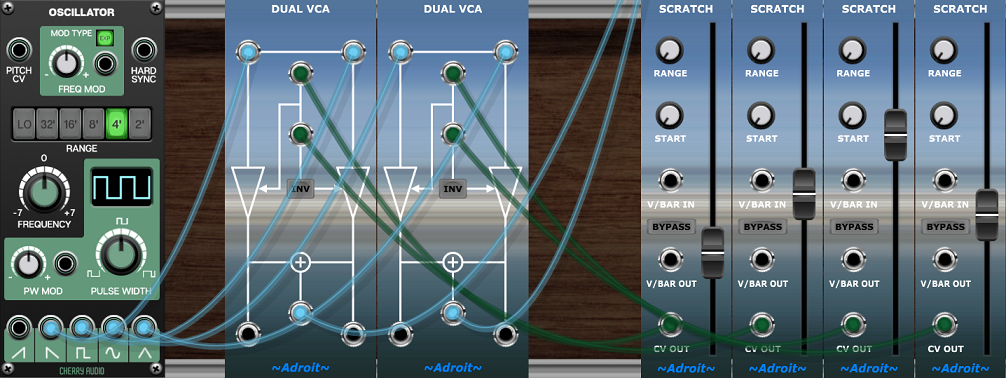
Finally, a simple general purpose CV OUT socket is provided that outputs a 0V to 5V signal that allows you to use the slider to control a wide range of functions. Here’s an example of a four-channel mixer…
Availability
The Scratch module is part of LSSP XL.